Apache Kafka ตอนที่ 1

Apache Kafka คือแพลตฟอร์มสำหรับการส่งข้อมูลแบบ Event Streaming โดยทั่วไปในการสื่อสารระหว่างระบบเราใช้ REST API เพื่อให้ Client ส่งข้อมูลตรงไปยัง Server ปลายทางแต่ใน Kafka รูปแบบจะต่างออกไป คือ Client จะส่งข้อมูลไปยัง Kafka Server แล้วระบบปลายทาง (ซึ่งเป็น Client เช่นกัน) จึงเข้ามาอ่านข้อมูลจาก Kafka เพื่อประมวลผลต่อภายหลัง
Kafka พัฒนาโดย LinkedIn ในปี 2011 ต่อมากลายเป็น Open Source ภายใต้ Apache Software Foundation ในปี 2012 ถูกนำในไปงานเช่น เก็บประวัติการใช้งาน, IoT

เป็น Event Streaming Platform หมายความว่ายังไง
Kafka มีความสามารถ 3 อย่าง
1. Publish (write) และ Subscribe to (read)
Kafka รองรับการทำงานแบบ multi-producer และ multi-consumer นั่นหมายความว่าหลายระบบสามารถเขียนข้อมูล (publish) เข้ามายัง Kafka ได้พร้อมกัน และในขณะเดียวกันหลายระบบก็สามารถสมัครรับข้อมูล (subscribe) เพื่อดึงไปใช้งานได้แบบไม่กระทบกัน เป็นการส่งข้อมูลที่ยืดหยุ่นและมีประสิทธิภาพสูง
2. เก็บข้อมูลเหตุการณ์ (Event) ได้ตามระยะเวลาที่ต้องการ
Kafka ไม่ได้แค่ส่งข้อมูลผ่าน ๆ ไปเท่านั้น แต่ยังสามารถ จัดเก็บข้อมูลไว้ภายในระบบ ตามระยะเวลาที่กำหนด (เช่น ชั่วโมง, วัน, หรือเป็นสัปดาห์) ทำให้ระบบปลายทาง (Consumer) สามารถเข้ามาอ่านย้อนหลังได้ตามต้องการ (Data Retention) แตกต่างจากระบบ queue โดยทั่วไป Message นั้นจะถูก ลบออกจาก Queue ทันที
3. รองรับการประมวลผลแบบเรียลไทม์และย้อนหลัง
Kafka สามารถ ประมวลผลข้อมูลแบบทันทีเมื่อเหตุการณ์ใหม่เข้ามา (real-time processing) และยังสามารถตั้งค่าให้ระบบกลับมาอ่านข้อมูลเก่าเพื่อประมวลผลย้อนหลังได้อีกด้วย ไม่ว่าจะเพื่อการวิเคราะห์ซ้ำ การกู้ข้อมูล หรือการพัฒนาระบบใหม่ที่ต้องการใช้ข้อมูลเดิม ก็สามารถทำได้สะดวก
สื่อสารข้อมูลแบบกระจาย (Distributed System) ออกแบบมาเพื่อรองรับการส่ง รับ และจัดเก็บข้อมูลประเภท เหตุการณ์ (Event) อย่างมีประสิทธิภาพ โดยสามารถใช้งานได้ทั้งบน Virtual Machines, Containers, On-Premises, และ Cloud Kafka ประกอบด้วย Servers และ Clients ที่สื่อสารกันผ่าน TCP protocol
Concepts
Event เหตุการณ์หรือเรียกว่า Message เป็นหน่วยข้อมูลที่ใช้ในการสื่อสารซึ่งสามารถถูกเขียน (write) หรือ อ่าน (read) อยู่ใน Topic สามารถถูกอ่านซ้ำได้หลายครั้งตามต้องการ ต่างจากระบบส่งข้อความแบบดั้งเดิมที่จะลบข้อมูลทันทีหลังจากมีการอ่าน ใน Kafka ข้อมูลจะยังคงอยู่แม้จะถูกอ่านไปแล้ว แทนที่ระบบจะลบ Event ทันทีหลังจากถูกอ่านเหมือนระบบ messaging แบบดั้งเดิมแต่ละ Event ประกอบด้วยข้อมูลสำคัญ เช่น
- Key: “Alice”
- Value: “Mad a payment of $200 to Bob”
- Timestamp: “Jun. 20, 2020 at 2:06 p.m.”
- Metadata headers (optional) เช่น ประเภทข้อมูล หรือข้อมูลเสริมอื่น ๆ
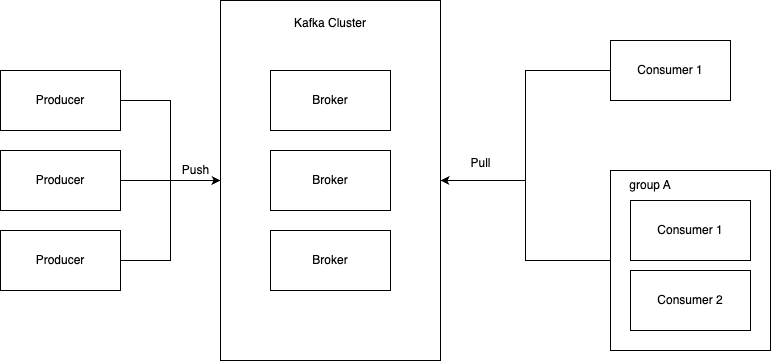
Producers คือ Client Applications ที่ทำหน้าที่ ที่ทำหน้าที่ Publish (เขียน) Messages ไปยัง Topics ใน Kafka Cluster โดยจะเป็นผู้กำหนด Topic และ Partition ที่จะส่ง Message ไปกรณีที่ไม่ระบุ Kafka จะกำหนดให้แบบ Round Robin หรือตาม Key ของ Message
Consumers คือ Client Applications ที่ทำหน้าที่ Subscribe (อ่าน) Messages จาก Topics ใน Kafka Cluster เพื่อนำไปประมวลผลต่อ โดยจัดกลุ่มเป็น Consumer Groups แต่ละ Partition ของ Topic จะถูกอ่านโดย Consumer เพียงตัวเดียวภายใน Consumer Group นั้นๆ เพื่อให้มั่นใจว่า Messages จะถูกประมวลผลเพียงครั้งเดียว (At-least-once Delivery) และตัว Consumer จะติดตาม Offset ของ Message ล่าสุดที่อ่านไปที่เก็บอยู่ใน Kafka Cluster เพื่อให้สามารถอ่าน Message ต่อไปได้อย่างถูกต้อง
Kafka ออกแบบให้ Producers และ Consumers แยกจากกันโดยสิ้นเชิง ซึ่งหมายความว่า Producer สามารถเขียน Event ได้โดยไม่ต้องรอให้ Consumer พร้อม หรือแม้กระทั่งไม่ต้องมี Consumer เลยก็ยังทำงานได้
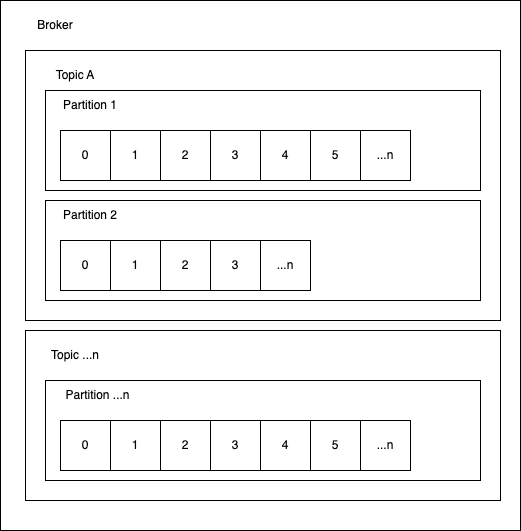
Topics เปรียบเสมือน หมวดหมู่ หรือ หัวข้อ สำหรับจัดเก็บ Stream ของข้อมูล Producer จะเขียน Messages ลงใน Topics และ Consumer จะอ่าน Messages จาก Topics
Partition แต่ละ Topic จะถูกแบ่งออกเป็น Partitions อย่างน้อยหนึ่ง Partition แต่ละ Message ภายใน Partition จะมี Offset ซึ่งเป็นตัวระบุตำแหน่งที่ไม่ซ้ำกัน
Offset ตำแหน่งของ Message ที่ถูกจัดเก็บเรียงตามลำดับภายใน Partition หนึ่งๆ ของ Topic โดย Offset จะเป็นตัวเลขที่ระบุตำแหน่งของแต่ละ Message เริ่มจาก 0, 1, 2, … และเพิ่มขึ้นเรื่อยๆ ตามลำดับการเข้ามาของ Message ใหม่ โดย Consumer จะใช้ Offset เพื่อติดตามว่าเคยอ่านข้อมูลถึงจุดไหนแล้ว ซึ่ง Kafka จะไม่ลบ Event หลังจากถูกอ่าน ทำให้สามารถย้อนกลับไปอ่าน Offset เดิมได้
Broker คือ Server หนึ่งตัวใน Kafka Cluster ทำหน้าที่รับ Messages จาก Producers, จัดเก็บ Messages ลงใน Partitions และให้บริการ Messages แก่ Consumers และจะมี Brokers หลายเครื่องทำงานร่วมกันในระบบจะเรียกว่า Kafka Cluster เพื่อให้ระบบมีความทนทานต่อความผิดพลาด (Fault Tolerance) และสามารถขยายขนาดได้ (Scalability) โดย Broker แต่ละตัวจะมี ID เป็นตัวระบุ
ZooKeeper สำหรับ (ใน Kafka เวอร์ชั่นเก่า) ทำหน้าที่ในการเลือก Controller Broker (ผู้นำในการจัดการ Partitions และ Replicas), การติดตามสถานะของ Brokers และ Topics
มีประสิทธิภาพที่คงที่แม้จะเก็บข้อมูลจำนวนมาก ไม่ได้ลดลงตามขนาดของข้อมูลที่จัดเก็บไว้ ทำให้สามารถเก็บข้อมูลในระยะยาวได้โดยไม่กระทบต่อความเร็วในการเขียนหรืออ่านข้อมูล
เพื่อให้ข้อมูลใน Kafka ทนต่อความผิดพลาด (fault-tolerant) และ พร้อมใช้งานสูง (highly-available) ทุก Topic สามารถถูก ทำสำเนา (replicate) ได้ โดยอาจกระจายไปยังหลาย Data Centers ซึ่งหมายความว่า จะมีหลาย Brokers ที่ถือข้อมูลชุดเดียวกันอยู่ เพื่อให้ระบบทำงานต่อได้แม้บาง Broker จะล่ม
| คุณสมบัติ | อธิบาย |
|---|---|
| Real-time | ข้อมูลถูกส่งและรับแทบจะทันที |
| Scalable | รองรับข้อมูลระดับ ล้านข้อความต่อวินาที โดยขยายเป็นหลายเครื่องได้ง่าย |
| Durable | ข้อมูลไม่หายง่าย ๆ เพราะถูกเก็บลงดิสก์แบบบันทึกตลอดเวลา |
| Distributed | ทำงานบนหลายเครื่องร่วมกัน (Cluster) เพื่อความเร็วและทนต่อความเสียหาย |
| High Throughput | ประมวลผลข้อมูลได้มหาศาลในเวลาสั้น |
| Replayable | ผู้บริโภค (Consumer) สามารถย้อนอ่านข้อมูลเก่าได้ |
Kafka ทำงานอย่างไร
- Source system คือระบบต้นทางที่ทำหน้าที่ส่งข้อมูล เช่น เซ็นเซอร์ IoT, Application, Website
- Producer คือ Kafka Client ที่ทำหน้าที่เขียนข้อมูลไปยัง Brokers ถูกใช้งานโดย Source system
- Broker คือ Kafka Server ที่จัดเก็บข้อมูล
- Consumer คือ Kafka Client ที่ทำหน้าที่อ่านข้อมูลจาก Brokers ถูกใช้งานโดย Target system
- Target system คือระบบปลายทางที่ทำหน้าที่ประมวลผลข้อมูล เช่น ระบบหลังบ้านของ Application หรือ Website, Elasticsearch
จะเห็นว่าจริงๆ แล้ว Kafka จะอยู่แค่ 3 จุดคือ Producer, Broker, Consumer
ถ้าเราเป็น Application เราจะมีโอกาสใข้งานแค่ฝั่งที่เป็น Client คือ Producer กับ Consumer รู้แค่จะเขียนกับอ่านข้อมูลยังไงก็เพียงพอต่อการนำไปใช้งานแล้ว
ถ้าเราเป็นคนดูแล Server เราจะเป็นคนที่ต้อง กำหนดค่า (configure) และ จัดการระบบ Kafka ด้วยตัวเอง โดยเฉพาะในสภาพแวดล้อมที่เป็นแบบ On-Premise หรือ Self-hosted ไม่ได้ใช้ Kafka แบบ Cloud Service